





Now that you're done learning some of the Basic Linux commands and how to use them to install Linux Software, it's time we showed you some of the other ways to work with Linux. Bear in mind that each distribution of Linux (Redhat, SUSE, Mandrake etc) will come with a slightly different GUI (Graphical User Interface) and some of them have done a really good job of creating GUI configuration tools so that you never need to type commands at the command line.
Vi Editor
For example, if you want to edit a text file you can easily use one of the powerful GUI tools like Kate, Kwrite etc., which are all like notepad in Windows though much more powerful; they have features such as multiple file editing and syntax highlighting (if you open an HTML file it understands the HTML tags and highlights them for you). However, you can also use the very powerful vi editor.
When first confronted by vi most users are totally lost, you open a file in vi (e.g vi document1) and try to type, but nothing seems to happen.. the system just keeps beeping!
Well that's because vi functions in two modes, one is the command mode, where you can give vi commands such as open a file, exit, split the view, search and replace etc., and the other mode is the insert view where you actually type text!
Don't be put off by the fact that vi doesn't have a pretty GUI interface to go with it, this is an incredibly powerful text editor that would be well worth your time learning... once you're done with it you'll never want to use anything else!
Realising that most people would find vi hard to use straight off, there is a useful little walk-through tutorial that you can access by typing vimtutor at a command line. The tutorial opens vi with the tutorial in it, and you try out each of the commands and shortcuts in vi itself. It's very easy and makes navigating around vi a snap. Check it out.
Grep
Another very useful Linux command is the grep command. This little baby searches for a string in any file. The grep command is frequently used in combination with other commands in order to search for a specific string. For example, if we wanted to check our web server's log file for a specific URL query or IP address, the 'grep' command would do this job just fine.
If, on the other hand, you want to find every occurence of 'hello world' in every .txt file you have, you would type grep "hello world" *.txt
You'll see some very common command structures later on that utilise 'grep'. At the same time, you can go ahead and check grep's man page by typing man grep , it has a whole lot of very powerful options.
PS - Process ID (PID) display
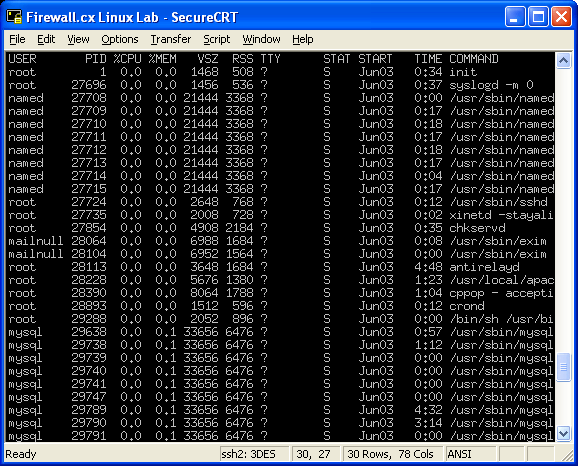
The ps command will show all the tasks you are currently running on the system, it's the equivalent of Windows Task Manager and you'll be happy to know that there are also GUI versions of 'ps'.
If you're logged in as root in your Linux system and type ps -aux , you'll see all processes running on the system by every user, however, for security purposes, users will only be able to see processes owned by them when typing the same command.
Again, man ps will provide you with a bundle of options available by the command.
Kill
The 'kill' command is complementary to the 'ps' command as it will allow you to terminate a process revealed with the previous command. In cases where a process is not responding, you would use the following syntax to effectively kill it: kill -9 pid where 'pid' is the Process ID (PID) that 'ps' displays for each task.
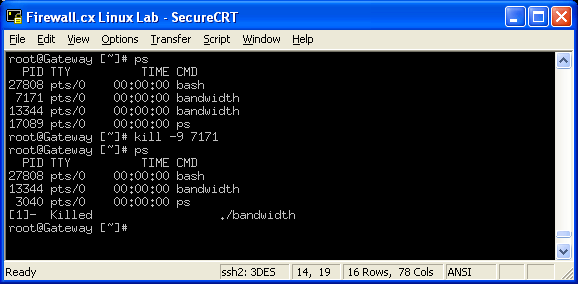
In the above example, we ran a utility called 'bandwidth' twice which is shown as two different process IDs (7171 & 13344) using the ps command. We then attempted to kill one of them using the command kill -9 7171 . The next time we ran the 'ps', the system reported that a process that was started with the './bandwidth' command had been previously killed.
Another useful flag we can use with the 'kill' command is the -HUP. This neat flag won't kill the process but pause it and at the same time force it to reload its configuration. So, if you've got a service running and need to restart it because of changes made in its configuration file, then the -HUP flag will do just fine. Many people look at it as an alternative 'reload' command.
The complete syntax to make use of the flag is: kill -HUP pid where 'pid' is the process ID number you can obtain using the 'ps' command, just as we saw in the previous examples.
Chaining Commands, Redirecting Output, Piping
In Linux, you can chain groups of commands together with incredible ease, this is where the true power of the Linux command line exists, you use small tools, each of which does one little task and passes the output on to the next one.
For example, when you run the ps aux command, you might see a whole lot of output that you cannot read in one screen, so you can use the pipe symbol ( | ) to send the output of 'ps' to 'grep' which will search for a string in that output. This is known as 'piping' as it's similar to plumbing where you use a pipe to connect two things together.
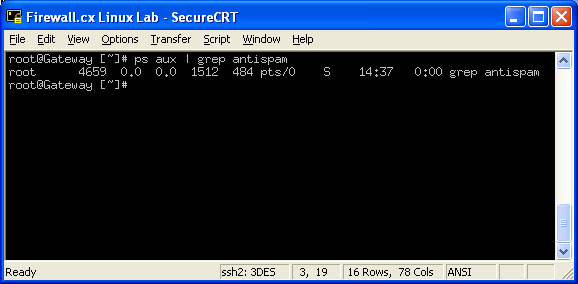
Say you want to find the task 'antispam' : you can run ps aux | grep antispam . Ps 'pipes' its output to grep and it then searches for the string, showing you only the line with that text.
If you wanted ps to display one page at a time you can pipe the output of ps to either more or less . The advantage of less is that it allows you to scroll upwards as well. Try this: ps aux | less . Now you can use the cursors to scroll through the output, or use pageup, pagedown.
Alias
The 'alias' command is very neat, it lets you make a shortcut keyword for another longer command. Say you don't always want to type ps aux | less, you can create an alias for it.. we'll call our alias command 'pl'. So you type alias pl='ps aux | less' .
Now whenever you type pl , it will actually run ps aux | less - Neat, is'nt it?
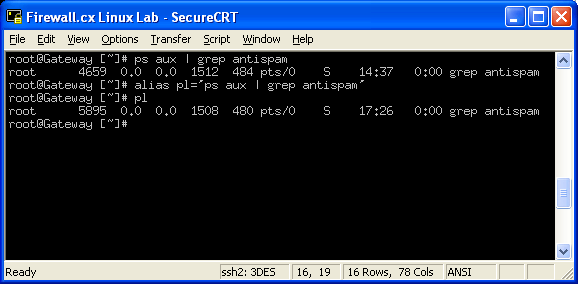
You can view the aliases that are currently set by typing alias:
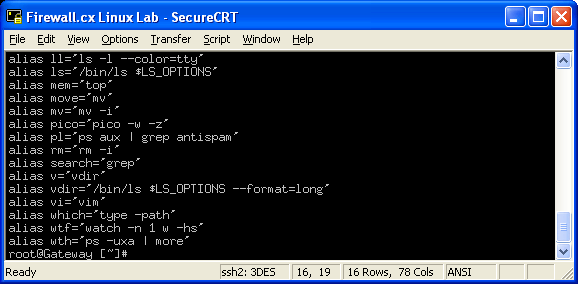
As you can see, there are quite a few aliases already listed for the 'root' account we are using. You'll be suprised to know that most Linux distributions automatically create a number of aliases by default - these are there to make your life as easy as possible and can be deleted anytime you wish.
Output Redirection
It's not uncommon to want to redirect the output of a command to a text file for further processing. In the good old DOS operating system, this was achieved by using the '>' operator. Even today, with the latest Windows operating systems, you would open a DOS command prompt and use the same method!
The good news is that Linux also supports these functions without much difference in the command line.
For example, if we wanted to store the listing of a directory into a file, we would type the following: ls > dirlist.txt:
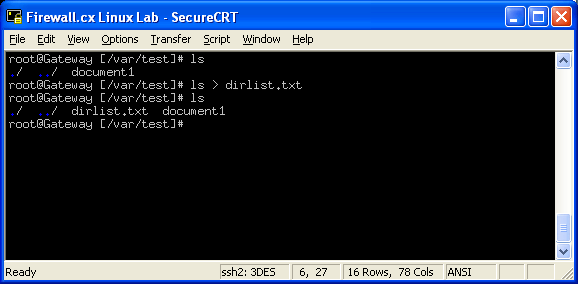
As you can see, we've taken the output of 'ls' and redirected it to our file. Let's now take a look and see what has actually been stored in there by using the command cat dirlist.txt :
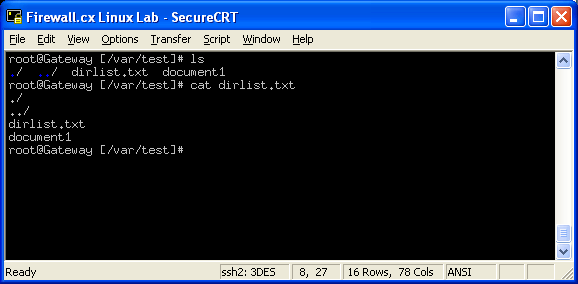
As expected, the dirlist.txt file contains the output of our previous command. So you might ask yourself 'what if I need to append the results?' - No problem here, as we've already got you covered.
When there's a need for appending files or results, as in DOS we simply use the double >> operator. By using the command it will append the new output to the file we have specified in the command line:
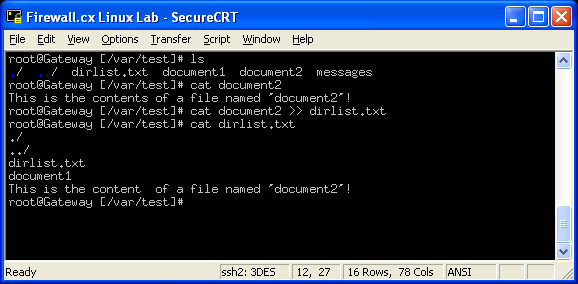
The above example clearly shows the content of our file named 'document2' which is then appended to the previously created file 'dirlist.txt'. With the use of the 'cat' command, we are able to examine its contents and make sure the new data has been appended.
Note:
By default, the single > will overwrite the file if it exists, so if you give the ls > dirlist.txt command again, it will overwrite the first dirlist.txt. However, if you specify >> it will add the new output below the previous output in the file. This is known as output redirection.
In Windows and DOS you can only run one command at a time, however, in Linux you can run many commands simultaneously. For example, let's say we want to see the directory list, then delete all files ending with .txt, then see the directory list again.
This is possible in Linux using one statement as follows : ls -l; rm -f *.txt; ls -l . Basically you separate each command using a semicolon, ';'. Linux then runs all three commands one after the other. This is also known as command chaining.
Background Processes
If you affix an ampersand '&' to the end of any command, it will run in the background and not disturb you, there is no equivalent for this in Windows and it is very useful because it lets you start a command in the background and run other tasks while waiting for that to complete.
The only thing you have to keep in mind is that you will not see the output from the command on your screen since it is in the background, but we can redirect the output to a file the way we did two paragraphs above.
For example, if you want to search through all the files in a directory for the word 'Bombadil', but you want this task to run in the background and not interrupt you, you can type this: grep "Bombadil" *.* >> results.txt& . Notice that we've added the ampersand '&' character to the end of the command, so it will now run in the background and place the results in the file results.txt . When you press enter, you'll see something like this :
$ grep "Bombadil" *.* >> results.txt&
[1] 1272
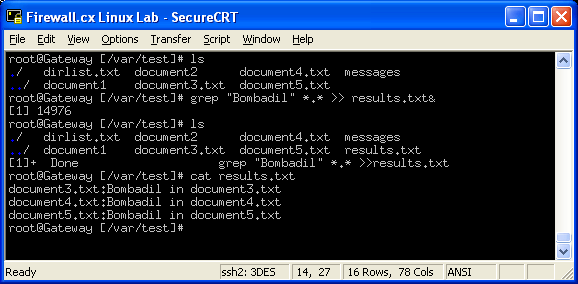
Our screen shot confirms this. We created a few new files that contained the string 'Bombadil' and then gave the command grep "Bombadil" *.* >> results.txt& . The system accepted our command and placed the process in the background using PID (Process ID) 14976. When we next gave the 'ls' command to see the listing of our directory we saw our new file 'results.txt' which, as expected, contained the files and lines where our string was found.
If you run a 'ps' while this is executing a very complex command that takes some time to complete, you'll see the command in the list. Remember that you can use all the modifiers in this section with any combination of Linux commands, that's what makes it so powerful. You can take lots of simple commands and chain, pipe, redirect them in such a way that they do something complicated!
Our next article covers Linux File & Folder Permissions, alternatively you can visit our Linux section for more linux related technical articles.
Enterprise-Class Cloud & Network Monitoring

Bandwidth Monitor

Wi-Fi Key Generator
Network and Server Monitoring

Follow Firewall.cx
Recommended Downloads
Cisco Password Crack
Decrypt Cisco Type-7 Passwords on the fly!
Free PatchManager

Firewall Analyzer
