






As discussed in the previous tutorial, we were made painfully aware that we were running out of IP address spaces and literally did in 2011. A new proposal or RFC was released for creation of a new addressing and network protocol that would improve this major issue and other issues that IPv4 couldn’t resolve.
RFC 1752, raised in the Toronto IETF meeting, explained the major changes that had to happen. It was adopted by IETF and IPv6 was established.
RFC 2460 was written specifically on IPv6 and we’ll follow it for study and analysis of the features. The features being discussed appear in similar order to those in the RFC. Let’s find out why IPv6 is being touted as the best thing since sliced bread.
Addressing Capability - Three Types of Addresses IPv6 Supports
Unicast
A unicast address identifies a single interface within the scope of the type of unicast address. With the appropriate unicast routing topology, packets addressed to a unicast address are delivered to a single interface. To accommodate load-balancing systems, it allows multiple interfaces to use the same address as long as they appear as a single interface to the IPv6 implementation on the host.
This in turn is further subdivided into the following types:
Unicast IPv6 addresses fall into one of five types:
- Global unicast addresses (which are conventional, publicly routable address, just like conventional IPv4 publicly routable addresses.)
- Link-local addresses (They are akin to the private, non-routable addresses in IPv4 (10.0.0.0/8, 172.16.0.0/12, 192.168.0.0/16). They are not meant to be routed, but confined to a single network segment. Link-local addresses mean you can easily throw together a temporary LAN, such as for conferences or meetings, or set up a permanent small LAN the easy way.)
- Site-local addresses (They are also meant for private addressing, with the addition of being unique, so that joining two subnets does not cause address collisions.)
- Special addresses (They are loopback addresses, IPv4-address mapped spaces, and 6-to-4 addresses for crossing from an IPv4 network to an IPv6 network.)
- Compatibility addresses (They are addresses to aid the migration of IPv4 to IPv6 and the coexistence of both types of hosts.)
Multicast
A multicast address identifies multiple interfaces. With the appropriate multicast routing topology, packets addressed to a multicast address are delivered to all interfaces that are identified by the address. A multicast address is used for one-to-many communication, with delivery to multiple interfaces.
In IPv6, multicast traffic operates in the same way that it does in IPv4. Arbitrarily located IPv6 nodes can listen for multicast traffic on arbitrary IPv6 multicast addresses. IPv6 nodes can listen to multiple multicast addresses at the same time. Nodes can join or leave a multicast group at any time.
IPv6 multicast addresses have the first 8 bits set to 1111 1111. An IPv6 address is easy to classify as multicast because it always begins with “FF.” Multicast addresses cannot be used as source addresses or as intermediate destinations in a Routing header. Beyond the first 8 bits, multicast addresses include additional structure to identify their flags, scope, and multicast group.
Anycast
An anycast address identifies multiple interfaces. With the appropriate routing topology, packets addressed to an anycast address are delivered to a single interface, the nearest interface that is identified by the address. The nearest interface is defined as being closest in terms of routing distance. An anycast address is used for one-to-one-of-many communication, with delivery to a single interface.
An anycast address is assigned to multiple interfaces. The routing infrastructure forwards packets that are addressed to an anycast address to the nearest interface to which the anycast address is assigned. To facilitate delivery, the routing infrastructure must track the interfaces that have been assigned anycast addresses and their distance in terms of routing metrics. At present, anycast addresses are used only as destination addresses and are assigned only to routers. Anycast addresses are assigned out of the unicast address space, and the scope of an anycast address is the scope of the type of unicast address from which the anycast address is assigned.
Simplification Of The Header Format
The header format has been simplified to reduce processing time by intermediate nodes. Several IPv4 headers have been dropped, some of which are ID, header length, flags, fragmentation offset and checksum. The ID flag has been removed as it was maintained in v4 as a part of fragmentation for intermediate nodes. Since by design fragmentation is not handled by intermediate nodes in IPv6, this field has been removed. The header length could change in v4 due to presence of options but in v6 the header length is kept constant at 6 octets. Options are taken as a part of the payload. Flags are not required in v6 as fragmentation cannot be set by intermediate nodes. Checksum is being handled by upper and lower level protocols either way apart from IPv4 so it was dropped in v6.
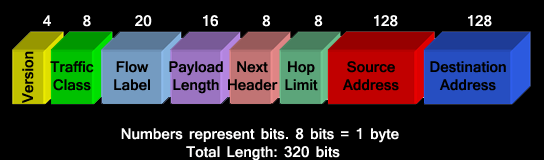
Figure above shows the IPv6 header format. The various fields and their sizes are as follows:
Flow Label (20 bits) is discussed later.
Payload Length (16 bits) is used to assign length. This is discussed later.
Next Header (8 bits) identifies the type of header that follows the IPv6 header.
Hop Limit (8 bits) is used to limit life of a packet on the network. This is discussed later.
Source and Destination Addresses (each 128 bits) assigns the source and destination addresses.
IPv6 Extension Headers
Further options for IPv6 headers are included in the extension headers. Each extension header is characterized by a certain value in the next header field in the preceding header. A IPv6 header may have zero, one or multiple extension headers. These headers are not processes by intermediate nodes unless they are specified by hop-by-hop option header. De-multiplexing occurs at the final destination and is done according to the content and semantics of the extension headers. If there are no extensions headers, the next header relates to the upper layer protocol header (which is the basic payload). Whether to process the next header is decided by the content of the extension header. Processing must follow the sequence of the extension headers. The only exception to this rule is the hop-by-hop option header. If this header is present this is processed ahead of any other extension header. Hence this is placed right after the IPv6 header with the next header value of the 6 header set to ‘0’. In case of multiple extension headers being present they occur in the following order:
Hop–by–hop, then
Destination option header (for processing by the first node), then
Routing header, then
Fragmentation header, then
Authentication header, then
Encapsulating security payload header, then
Destination option header (for processing by the final destination), then
Upper layer protocol header.
Each header can only occur once except the destination option header. It can occur twice, once right after the IPv6 header and again before the upper layer protocol header. The general format of an extension header is shown in the figure below:
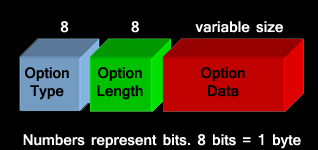
The structure and functionality is as follows:
The type and function of each extension header is discussed in subsequent sections.
Hop–by–Hop Option Header
This header is placed after the IPv6 header and is processed by all link nodes. This has a next header value of ‘0’. The only options are pad1 and padn option. In order to align a packet, an option header of padding is used. Pad1 is used to create one octet padding whereas padN is used to create ‘n’ octet padding.
Routing Header
This header is analogous to IPv4 loose routing / record route header. This has a next header value of ‘43’. The format of a routing header is shown in figure below:
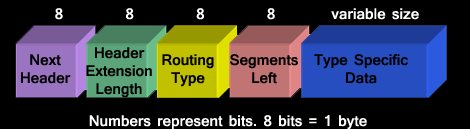
Explanation of the header is as follows:
While processing, if the routing is unrecognizable by a link node it checks for the number of segments left. If that value is ‘0’, then the link node processes the next header. If the segments left field has a non ‘0’ value, then the packet is discarded and an ICMP message with ‘unrecognizable route option’ is sent to the source. If a node finds that the MTU is less for a packet to be sent to the next node, then it is discarded as well.
The point worth noting here is that PMTU calculation is done before sending a packet, and fragmentation is maintained only by source and destination. So it can be presumed that the packet size will conform to the outgoing PMTU. So this kind of discarding of a packet for not conforming to PMTU is contradictory.
Routing formats: Type ‘0’ routing header format is displayed below:
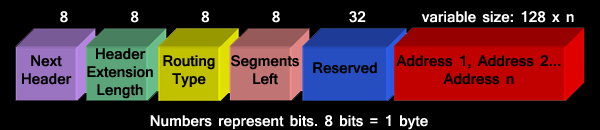
The basic explanation of the fields of the routing has already been done. The only difference here is the reserved field of 32 bits, which is ignored while processing by the link nodes.
A routing header is not processed until it reaches a node which is mentioned as one of the addresses in the address fields. This is checked by the destination address field. If a destination address field and an intermediate address is the same then, as directed by the next header in the hop-by-hop header, processing reaches the routing header. The node then checks if the segments left values is ‘0’.
If yes, then it proceeds to the next header which can be the upper layer protocol header. If no, then the following algorithm is maintained:
if Segments Left = 0 {
proceed to process the next header in the packet, whose type is
identified by the Next Header field in the Routing header
}
else if Hdr Ext Len is odd {
send an ICMP Parameter Problem, Code 0, message to the Source
Address, pointing to the Hdr Ext Len field, and discard the
packet
}
else {
compute n, the number of addresses in the Routing header, by
dividing Hdr Ext Len by 2
if Segments Left is greater than n {
send an ICMP Parameter Problem, Code 0, message to the Source
Address, pointing to the Segments Left field, and discard the
packet
}
else {
decrement Segments Left by 1;
compute i, the index of the next address to be visited in
the address vector, by subtracting Segments Left from n
if Address [i] or the IPv6 Destination Address is multicast {
discard the packet
}
else {
swap the IPv6 Destination Address and Address[i]
if the IPv6 Hop Limit is less than or equal to 1 {
send an ICMP Time Exceeded -- Hop Limit Exceeded in
Transit message to the Source Address and discard the
packet
}
else {
decrement the Hop Limit by 1
resubmit the packet to the IPv6 module for transmission
to the new destination
}
}
}
}
(Courtesy: RFC 2460, www.ietf.org)
The algorithm works as follows: At each link node having the same address as the destination address of the incoming packet, the segments left value is checked for a non ‘0’ value. If found true, then a value n = (header length)/2 is calculated. At each respective node, value of segments left is recalculated as segments left = segments left -1. To pick the next address from the list carried by the packet, a value i is calculated as i = segments left – n. Now the ith address from the array is taken and swapped with the destination address field. Hence the table is maintained throughout the path.
The problem with this is that the table values are not removed and the burden of the array is carried along the entire path. If this is to ensure a record route option then the above algorithm does not serve the purpose. If this is to ensure a packet follows a particular path, then addresses of nodes already visited are of no during processing by intermediate nodes which have not been visited yet. An alternate algorithm which reduces the load as a packet passes through nodes listed in the address array can be implemented. On reaching a node, if the destination address matches the node address a node processes the segments left field. On a non ‘0’ value, it processes the topmost address of the address list.
If found valid, this new address is swapped with the destination address field, the hop limit is decremented by 1 and the segments left is decremented by 1. The topmost address from the list is now removed and the next address is incremented to its position. This allows incremental reduction of load on a packet and by the time it reaches its final destination the list holds only 1 address, which should be the same as the final destination.
Fragmentation Header
Fragmentation in IPv6 is analogous in functionality in IPv4. The only difference is that this is handled by only the source and destination nodes. Intermediate link nodes are not allowed to fragment packets. The header format is shown in the figure below:
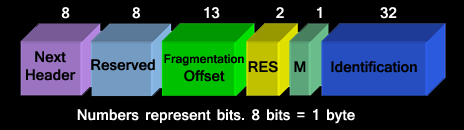
Next Header (8 bits): The next header contains the type of header following the fragmentation header.
Each packet has two parts:
Unfragmentable Part: the IPv6 header which does not change in any of the fragments and is carried by all of the fragments.
PL.ORIG = PL.FIRST – FL.FIRST – 8 + (8*FO.LAST) + FL.LAST (courtesy:RFC2460, www.ietf.org)
where:
PL.ORIG = payload length of the reassembled packet.
Reassembly of packets is discarded under the following conditions:
- If all the fragments do not arrive at their destination within the first 60 seconds from the time of arrival of the first fragment.
- For a fragment whose M flag is set to 1, and the packet is not a multiple of 8 octets as calculated from the packet’s payload length.
- If a fragment, after reassembly makes a whole packet size greater than 65535 octets.
Destination Option Header
This header is only processed by the destination node. This is the only header which can occur twice, once just after the hop-by-hop option header, and once before the actual payload. It has a next header value of 60.
No Next Header
This header has a next header value of 59. This signifies that there is no header following the header whose next header value is 59. If the IPv6 header payload depicts data beyond such a header, it is passed unchanged for forwarding.
This ends the discussion on the various types of header formats and their subsequent uses in the v6 header. A major improvement in IPv6 has been the packet size management and transmission unit calculation. The next section deals with these two issues.
Packet Size & MTU Issues
IPv6 needs to have every link on the internet to have an MTU of 1280 octets which is 1280 bytes. Any link that cannot conform to this value needs to have the lower layer protocol manage some form of fragmentation and reassembly below the Ipv6 protocol layer. It has been recommended that higher layer protocols with configurable MTU should have it set to 1280 bytes. It is preferable to have it set to 1500 bytes to utilize encapsulation facility without fragmentation.
An Ipv6 node should be able to implement PMTU discovery (RFC 1981). If this is not available then it should restrict to the minimum size of 1280 bytes. Fragmentation algorithm is to be followed for a node trying to send a packet of size bigger than the PMTU. But if an upper layer protocol can resize its segments to match the PMTU, it should be followed. Problem is, once PMTU is discovered using the algorithm detailed in RFC 1981, how do we conform to the upper layer to start constructing segments which will match the PMTU? No specific communication protocol has been designed to send PMTU information to upper layer protocols.
Flow Label
A new field in the IPv6 header is the flow label. This is used to assign a label to all traffic which requires the same level of handling, e.g. ‘real time’ traffic. Problems arise in the level of priority handling of such packets. Instances where routers and hosts don’t support flow labelling, this field is set to ‘0’ and routers ignore it. So there is a question of recognizing the feature. A router which does not recognize this feature ignores the value.
A flow label is identified by a set of same source address, destination address and a flow label. If any packet has the hop-by-hop option set, then all packets belonging to the same flow must have the same option, except the value of the next header field. If any packet in the flow has a routing header, then all packets in the same flow must have the same content up to and including the routing header, except the value of the next header field. So the problem is that the burden of a hop-by-hop or routing header requirements of any one packet in a flow has to be borne by all the packets in that flow, whether or not it applies to them. Flow label recovery after a router has crashed is also difficult, while keeping in mind the time constraints and domain of values within a given time frame.
Traffic Classes
This field is analogous to the TOS field in IPv4 headers. This is created to provide the same type of functionality.
Upper Layer Checksum Issues
Any upper layer protocol which also takes into account the IP addresses, while calculating checksum, needs to modify its checksum calculating algorithm to accommodate 128 bit addresses instead of 32 bit addresses.
Maximum Payload Size
While calculating the maximum payload size, an upper layer protocol has to take into account the header size of the v6 header. Hence a TCP segment can have a maximum size of 60 bytes less than the PMTU calculated. This is to accommodate 40 octets of the IPv6 header and 20 octets for the TCP header.
Responding the Packets Carrying Routing Headers
Certain methods have to be followed while a response packet is being sent to an incoming packet carrying a routing header. When an upper layer protocol is responding to a packet which carried a routing header, the response packet generated will not carry a routing header by reversing the order of addresses found in the routing header of the incoming packet. The only exceptions to this rule are:
Response To Packets Not Carrying A Routing Header
Packets having a routing header supplied by the local configuration, which was not generated by reversing the address list found in the incoming packet to which this response packet is being generated. Routing headers generated by reversing the list of the routing header in an incoming packet, if, and only if, the incoming packet carried an authentication header and has been verified by the receiver.
About The Writer
Arani Mukherjee holds a Master’s degree in Distributed Computing Systems from the University of Greenwich, UK and works as network designer and innovator for remote management systems, for a major telecoms company in UK. He is an avid reader of anything related to networking and computing. Arani is a highly valued and respected member of Firewall.cx, offering knowledge and expertise to the global community since 2005.
Your IP address:
216.73.216.214
All-in-one protection for Microsoft 365

FREE Hyper-V & VMware Backup

Wi-Fi Key Generator
Network and Server Monitoring

Follow Firewall.cx
Recommended Downloads
Cisco Password Crack
Decrypt Cisco Type-7 Passwords on the fly!
Bandwidth Monitor

Free PatchManager

Security Podcast

Firewall Analyzer
