Distance Vector routing protocols use frequent broadcasts (255.255.255.255 or FF:FF:FF:FF) of their entire routing table every 30 sec. on all their interfaces in order to communicate with their neighbours. The bigger the routing tables, the more broadcasts. This methodology limits significantly the size of network on which Distance Vector can be used.
Routing Information Protocol (RIP) and Interior Gateway Routing Protocol (IGRP) are two very popular Distance Vector routing protocols. You can find links to more information on these protocols at the bottom of the page. (That's if you haven't had enough by the time you get there !)
Distance Vector protocols view networks in terms of adjacent routers and hop counts, which also happens to be the metric used. The "hop" count (max of 15 for RIP, 16 is deemed unreachable and 255 for IGMP), will increase by one every time the packet transits through a router.
So the router makes decisions about the way a packet will travel, based on the amount of hops it takes to reach the destination and if it had 2 different ways to get there, it will simply send it via the shortest path, regardless of the connection speed. This is known as pinhole congestion.
Below is a typical routing table of a router which uses Distance Vector routing protocols:

Let's explain what is happening here:
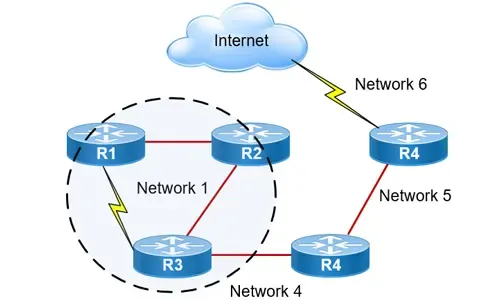
In the above picture, you see 4 routers, each connected with its neighbour via some type of WAN link e.g ISDN.
Now, when a router is powered on, it will immediately know about the networks to which each interface is directly connected. In this case Router B knows that interface E0 is connected to the 192.168.0.0 network and the S0 interface is connected to the 192.168.10.0 network.
Looking again at the routing table for Router B, the numbers you see on the right hand side of the interfaces are the "hop counts" which, as mentioned, is the metric that distance vector protocols use to keep track on how far away a particular network is. Since these 2 networks are connected directly to the router's interface, they will have a value of zero (0) in the router's table entry. The same rule applies for every router in our example.
Remember we have "just turn the routers on", so the network is now converging and that means that there is no data being passed. When I say "no data" I mean data from any computer or server that might be on any of the networks. During this "convergence" time, the only type of data being passed between the routers is that which allows them to populate their routing tables and after that's done, the routers will pass all other types of data between them. That's why a fast convergence time is a big advantage.
One of the problems with RIP is that it has a slow convergence time.

Let's explain the above diagram:
In the above picture, the network is said to have "converged", in other words, all routers on the network have populated their routing table and are completly aware of the networks they can contact. Since the network is now converged, computers in any of the above networks can contact each other.
Again, looking at one of the routing tables, you will notice the network address with the exit interface on the right and next to that is the hop count to that network. Remember that RIP will only count up to 15 hops, after which the packet is discarded (on hop 16).
Each router will broadcast its entire routing table every 30 seconds.
Routing based on Distance Vector can cause a lot of problems when links go up and down, this could result in infinite loops and can also de-synchronise the network.
Routing loops can occur when every router is not updated close to the same time.
Let's have a look at the problem before we look at the various solutions:
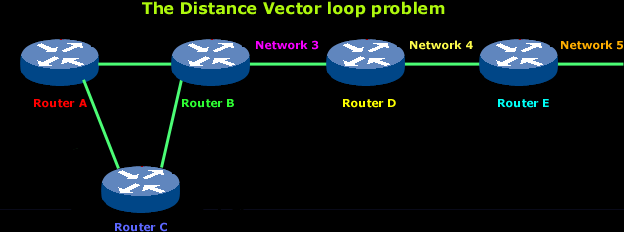
Let's explain the above:
In the above picture you can see 5 routers of which routers A and B are connected with Router C, and they all end up connecting via routers D and E to Network 5.
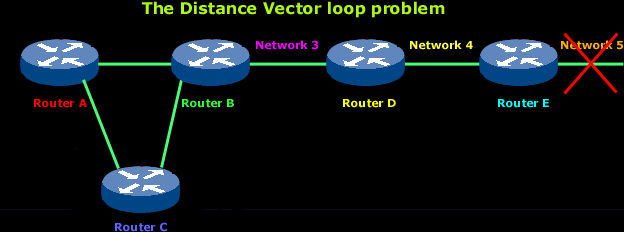
As the above diagram shows, Network 5 suddenly fails.
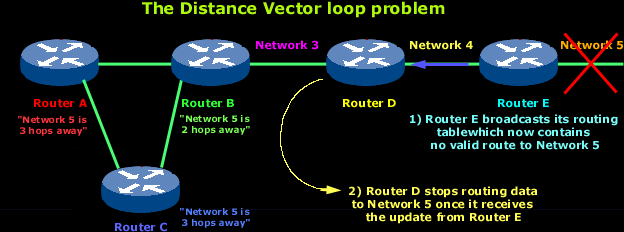
All routers know about Network 5 from Router E. For example, Router A, in its tables, has a path to Network 5 through routers B, D and E.
When Network 5 fails, Router E knows about it since it's directly connected to it and tells Router D about it on its next update (when it will broadcast its entire routing table). This will result in Router D stopping routing data to Network 5 through Router E. But as you can see in the above picture, routers A B and C don't know about Network 5 yet, so they keep sending out update information. Router D will eventually send out its update and cause Router B to stop routing to Network 5, but routers A and C are still not updated. To them, it appear that Network 5 is still available through Router B with a metric of 3 !
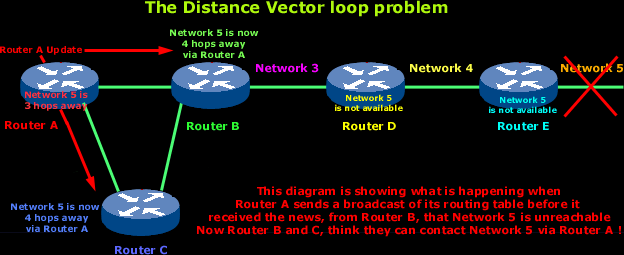
Now Router A sends its regular broadcast of its entire routing table which includes reachability for Network 5. Routers C and B receive the wonderful news that Network 5 can be reached from Router A, so they send out the information that Network 5 is now available !
From now on, any packet with a destination of Network 5 will go to Router A then to Router B and from there back to Router A (remember that Router B got the good news that Network 5 is available via Router A).
So this is where things get a bit messy and you have that wonderful loop, where data just gets passed around from one router to another. Seems like they are playing ping pong :)
To deal with these problems we use the following techniques:
Maximum Hop Count
The routing loop we just looked at is called "counting to infinity" and it is caused by gossip and wrong information being communicated between the routers. Without something to protect against this type of a loop, the hop count will keep on increasing each time the packet goes through a router ! One way of solving this problem is to define a maximum hop count. Distance Vector (RIP) permits a hop count of up to 15, so anything that needs 16 hops is unreachable. So if a loop occurred, it would go around the network until the packet reached a hop count of 15 and the next router would simply discard the packet.
Split Horizon
Works on the principle that it's never useful to send information about a router back to the destination from which the original packet came. So if for example I told you a joke, it's pointless you telling me that joke again !
In our example it would have prevented Router A from sending the updated information it received from Router B back to Router B.
Route Poisoning
Alternative to split horizon, when a router receives information about a route from a particular network, the router advertises the route back to that network with the metric of 16, indicating that the destination is unreachable.
In our example, this means that when Network 5 goes down, Router E initiates router poisoning by entering a table entry for Network 5 as 16, which basically means it's unreachable. This way, Router D is not susceptible to any incorrect updates about the route to Network 5. When Router D receives a router poisoning from Router E, it sends an update called a poison reverse, back to Router E. This make sure all routes on the segment have received the poisoned route information.
Route poisoning, used with hold-downs (see section below) will certainly speed up convergence time because the neighboring routers don't have to wait 30 seconds before advertising the poisoned route.
Hold-Down Timers
Routers keep an entry for the network-down state, allowing time for other routers to recompute for this topology change, this way, allowing time for either the downed router to come back or the network to stabilise somewhat before changing to the next best route.
When a router receives an update from a neighbor indicating that a previously accessible network is not working and is inaccessible, the hold-down timer will start. If a new update arrives from a neighbor with a better metric than the original network entry, the hold-down is removed and data is passed. But an update is received from a neighbor router before the hold-down timer expires and it has a lower metric than the previous route, therefore the update is ignored and the hold-down timer keeps ticking. This allows more time for the network to converge.
Hold-down timers use triggered updates, which reset the hold-down timer, to alert the neighbor's routers of a change in the network. Unlike update messages from neighbor routers, triggered updates create a new routing table that is sent immediatley to neighbor routers because a change was detected in the network.
There are three instances when triggered updates will reset the hold-down timer:
1) The hold-down timer expires
2) The router received a processing task proportional to the number of links in the internetwork.
3) Another update is received indicating the network status has changed.
In our example, any update received by Router B from Router A, would not be accepted until the hold-down timer expires. This will ensure that Router B will not receive a "false" update from any routers that are not aware that Network 5 is unreachable. Router B will then send a update and correct the other routers' tables.
Distance Vector protocol covered here on Firewall.cx include:
Free eBook - Endpoint Security

Enterprise-Class Cloud & Network Monitoring

Bandwidth Monitor

Wi-Fi Key Generator
Network and Server Monitoring

Follow Firewall.cx
Recommended Downloads
Cisco Password Crack
Decrypt Cisco Type-7 Passwords on the fly!
Automated Patching Solution

Firewall Analyzer